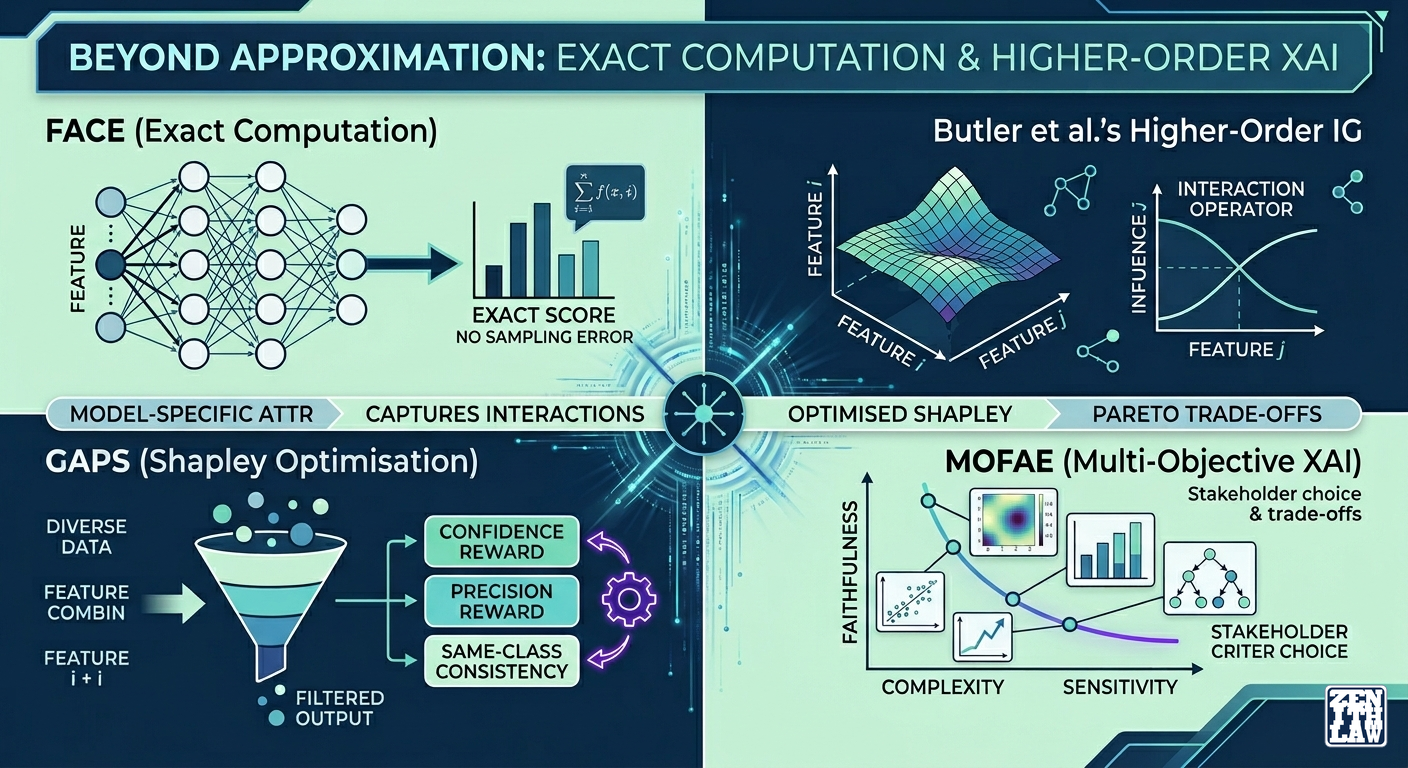
Standard attribution methods are approximate: they sample, they perturb, they linearise. Four recent papers abandon approximation in favour of exact computation, higher-order interaction modelling, explicit optimisation of evaluation criteria, and multi-objective trade-off surfaces. One computes exact attributions for feedforward networks. Another extends Integrated Gradients to capture feature interactions via operator theory. A third optimises Shapley-value rewards for generality and precision directly. The fourth treats explanation quality as a multi-objective problem with conflicting criteria. Each method addresses a specific limitation of standard attributions within defined boundaries, and each reveals different facets of what it means for an attribution to be good.
Introduction
Standard attribution methods approximate. They sample, perturb, and linearise because they treat the model as a black box. The four papers reviewed here abandon different dimensions of that approximation: Carles-Bou and Carmona replace model agnosticism with exact computation for known architectures. Butler et al. extend Integrated Gradients beyond first-order effects to capture feature interactions. Daley et al. replace passive Shapley calculation with direct optimisation for evaluation criteria. Wang et al. treat explanation quality as a multi-objective problem, acknowledging that no single explanation balances all desiderata.
None of these methods is a drop-in replacement for standard SHAP [5] or LIME [6]. Each makes deliberate trade-offs in architectural specificity, computational cost, and output interpretability. The sections below examine the core mechanism and evidentiary basis of each method so you can assess which trade-offs fit your use case.
This article is not legal advice.
Technical Terminology for Exact Methods
- Model-specific attribution
- An attribution method that exploits knowledge of the model architecture (e.g., activation functions, weight matrices) to compute explanations, as opposed to model-agnostic methods that treat the model as a black box.
- Higher-order attribution
- An attribution that captures interactions between features, typically by computing second-order (or higher) derivatives that measure how the importance of one feature changes with the value of another.
- Piecewise-linear network
- A neural network using activation functions such as ReLU that partition the input space into linear regions, within which the network behaves as a linear function of its inputs.
- Pareto front
- The set of solutions in a multi-objective optimisation problem where no single objective can be improved without degrading another, providing a spectrum of acceptable trade-offs rather than a single best solution.
- Generality (in attribution)
- The consistency of an attribution across instances of the same class: a general explanation assigns similar importance to similar features for similar predictions.
- Precision (in attribution)
- The degree to which an attribution avoids assigning importance to features that would support a different class: a precise explanation is specific to the predicted class.
Four Routes Beyond Approximation
Carles-Bou and Carmona (2026): Exact Attribution Through Architecture Exploitation
FACE (Feature Attribution Computed Exactly) exploits the piecewise-linear structure of feedforward ReLU networks to compute attributions exactly [2]. For any input, the activation pattern of each neuron determines which linear region the point falls into. Within that region, the network reduces to a single linear transformation of the composite weight matrices. Attribution is the Hadamard product of the composite weight matrix with the input. No sampling. No perturbation. No approximation.
The most striking result is that exact computation is cheaper than approximation. FACE requires only a single forward pass plus matrix operations to build the composite weight matrix, making it 1 to 2 orders of magnitude faster than LIME and kernelSHAP. Perfect fidelity (ICC2 = 1.000) follows necessarily from the exact computation. It is a mathematical property of the method, not an empirical achievement, and holds by construction for any input within a linear region.
Core trade-off: This is architecture-specific. It works for feedforward ReLU networks only. Convolutional networks, transformers, and recurrent architectures are not covered. White-box weight access is required.
Study limitations: The mathematical derivation of exact FNN attribution is sound. The fidelity and speed advantages are verified within the experimental scope of the paper. But three architectural constraints bound the applicability of the method: FACE requires (a) feedforward architecture, excluding convolutional, recurrent, attention, and residual networks, (b) piecewise-linear activations (sigmoid or tanh require approximation that undermines the exactness guarantee), and (c) white-box weight access. Two precision-related caveats also apply: at ReLU boundaries the attribution is exact only for the chosen linear region, and finite-precision arithmetic introduces numerical error for very deep networks, though this is negligible at tested depths. Scalability to very deep networks and generalisation beyond piecewise-linear activations remain unconfirmed as of the published results.
Butler, Feng and Djurić (2026): Higher-Order Attribution Through Operator Theory
Standard Integrated Gradients captures first-order effects: how much does changing a feature change the output? But the importance of one feature may depend on the value of another. Those interactions are invisible to first-order methods. [1] Consider a model where the prediction depends on the product of three features (3x₁x₂x₃). First-order IG assigns importance to each xᵢ individually but cannot distinguish this multiplicative structure from a simple additive contribution. Higher-order attribution reveals the joint interaction directly. This paper develops an operator-theoretic framework that extends Integrated Gradients to higher orders. First-order attribution becomes a linear operator Aᵢ applied to f(x). Second-order is AᵢAⱼf(x), yielding the Integrated Hessian. Higher orders follow the same pattern.
The framework satisfies linearity, symmetry, marginalisation (summing second-order attributions recovers first-order), and completeness. The marginalisation property is practically important: practitioners can compute first-order attributions using standard IG, then optionally expand to higher orders without changing the base attributions. This backward-compatibility lowers the adoption barrier.
The paper also draws an explicit connection between XAI and topological signal processing: first-order attributions correspond to node signals on a graph, second-order to edge signals, and higher-order terms to simplicial complexes. On a housing valuation dataset, second-order attribution graphs reveal clusters of jointly-acting features that would be invisible to first-order methods.
Practical constraint: Higher-order attributions multiply cost. Second-order requires O(d²) computations for d features.
Study limitations: The operator-theoretic unification is mathematically elegant and the axiomatic properties are proven. Empirical validation is limited to two small tabular experiments. Behaviour on high-dimensional data and computational tractability at scale remain unconfirmed.
Daley et al. (2022): GAPS: Attribution as Optimisation
If we know the evaluation criteria, why not optimise for them directly? That is the premise, but the criteria themselves embed design choices. [3] GAPS (Generality and Precision Shapley Attributions) introduces a reward function combining three terms: confidence expectation (how confident is the model given this feature subset?), same-class confidence reward (does the explanation produce high confidence for the correct class?), and opposite-class penalty (does it inadvertently produce high confidence for the wrong class?). The coefficients of this three-term objective become the attribution scores, computed via KernelSHAP-weighted linear regression. The definition of generality and precision is built into the reward structure, and different definitions would yield different attributions.
On the UNSW-NB15 cybersecurity dataset, GAPS outperforms both LIME and SHAP on generality and precision. On the ICS Power System dataset, GAPS outperforms LIME but does not consistently outperform SHAP. The benefit is domain-dependent.
Study limitations: GAPS requires defining what generality and precision mean for the specific task, introduces three hyperparameters, and has been evaluated only on binary classification with Random Forest classifiers. The architecture-agnostic reward function of the method makes it potentially applicable beyond RF, but this has not been demonstrated. The paper lacks theoretical guarantees about convergence or uniqueness. The comparative advantage over LIME and SHAP is partial: it holds on one of two datasets. Generalisation to multi-class, deep learning, and regression settings is unconfirmed.
Wang et al. (2024): MOFAE: Attribution as Multi-Objective Optimisation
What if explanation quality has multiple, conflicting dimensions, and no single explanation can maximise them all? [4] MOFAE treats attribution as a multi-objective optimisation problem with three objectives: faithfulness (how well the explanation predicts model behaviour under feature removal), average sensitivity (stability under perturbation), and complexity (simplicity measured via entropy). The NSGA-III evolutionary algorithm evolves a population of candidate explanation vectors, producing a Pareto front of explanations rather than a single output.
Across 8 UCI tabular datasets, MOFAE solutions dominate competitor methods in 33.72% to 80.20% of pairwise comparisons while being dominated only 0% to 0.07% of the time. The Pareto front reveals qualitatively different explanations at its extremes: high-faithfulness explanations use many features; low-complexity ones focus on few.
Notable limitation: on German Credit, MOFAE solutions dominate Integrated Gradients in only 0.03% of comparisons. For datasets with strong inherent structure, gradient-based methods are already near-optimal on all three objectives, and the multi-objective search has little room to improve.
Deployment constraint: Each explanation requires a full evolutionary run (~6 seconds for small tabular datasets). This limits real-time applicability. Interpreting the Pareto front also requires domain expertise.
Study limitations: The finding that explanation quality metrics are inherently conflicting is a significant empirical result validated across multiple datasets. Real-time applicability is unconfirmed: the computational cost of NSGA-III is prohibitive for interactive settings.
Cross-Paper Synthesis: Four Strategies for Better Attribution
In my reading, the result of FACE that exact computation is cheaper than approximation is the most underappreciated finding in this set. The usual assumption is that exactness costs more. FACE shows it can cost less, provided you are willing to commit to a specific architecture.
The approximation spectrum
The four papers occupy distinct positions on a spectrum from full model access to complete agnosticism:
| Method | Model access | Approximation | Computation | Generality |
|---|---|---|---|---|
| FACE | White-box (weights) | None (exact) | Very fast | FNN only |
| Higher-Order IG | White-box (gradients) | Linear approx. at each order | O(d²) per order | Any differentiable model |
| GAPS | Black-box (predictions) | Shapley approx. via sampling | Modest | Any model (tested RF only) |
| MOFAE | Black-box (predictions) | Evolutionary search | Expensive (~6s per point) | Any model |
No single method dominates. The choice depends on what the practitioner knows about the model, how much computation they can afford, and which aspects of explanation quality matter most for their use case.
The interaction blind spot
First-order attribution, the default for LIME, SHAP, and Integrated Gradients, misses interactions by construction. Butler et al. provide a theoretical framework for going beyond first order, but the computational cost scales quadratically. MOFAE can in principle capture interactions through the faithfulness objective, since a faithful explanation of a highly interactive model would need to reflect those interactions. But none of these methods makes interactions easy to visualise or communicate to non-expert stakeholders.
Optimisation vs. computation
A deeper distinction separates FACE and Higher-Order IG (which compute attributions) from GAPS and MOFAE (which optimise them). Computing an attribution assumes there is a ground-truth importance that the method should recover. Optimising an attribution assumes there are multiple desirable properties and the method should find a point in trade-off space. These are philosophically different positions. The evaluation literature (covered in a forthcoming article on metrics and benchmarks) has not yet settled which framing is more productive.
The missing pieces
- Large-scale validation: None of these methods has been demonstrated on models with more than tens of millions of parameters.
- User studies: None evaluates whether the improved attributions lead to better human decision-making.
- Temporal and sequential data: All four methods are designed for static, tabular or image inputs.
Questions on Attribution Methods
Can FACE be extended to transformers?
Not directly. Transformers use attention mechanisms and layer normalisation, which do not produce piecewise-linear regions in the same way as ReLU-activated feedforward networks. A transformer-specific exact method would require a different mathematical approach.
How does the Pareto front of MOFAE help a practitioner?
It forces explicit trade-off decisions. A healthcare deployment might prioritise faithfulness (the explanation must accurately reflect the model) over complexity (the explanation can be long). A consumer-facing product might invert those priorities. MOFAE generates both options and lets the domain expert choose, rather than hiding the trade-off inside a single score.
Is the reward function of GAPS architecture-dependent?
The reward function operates on model predictions, which are available for any architecture. The restriction of the paper to Random Forest is a choice about experimental scope, not a limitation of the method.
Does higher-order attribution always improve explanation quality?
Not necessarily. Higher-order terms increase interpretability cost: a stakeholder who struggles to understand first-order attributions will be overwhelmed by second-order interaction maps. The value of higher-order attribution depends on whether feature interactions are materially important for the decision. This question can be answered empirically before deploying the explanation method.
Which of these methods is closest to production-ready?
FACE is the most mature for its target architecture (FNNs) and offers a clear advantage over approximations. MOFAE and higher-order IG require further scalability work. GAPS needs broader validation across model types and domains.
Conclusion
The four papers share a common shift: away from universal applicability and toward stronger, scoped guarantees. FACE offers exactness for feedforward networks. Higher-order IG captures interactions at a cost. GAPS optimises for known criteria. MOFAE makes trade-offs explicit. This is a maturing field, not a fragmenting one.
The open question, covered in a forthcoming article on metrics and benchmarks, is whether these methods actually produce better explanations than the approximate alternatives they seek to replace. The answer depends on evaluation, and evaluation is where the unresolved problems of the field concentrate.
Part 2 of a series on feature attribution, explainability, and interpretability. Technical and educational content. Not legal, regulatory, or procurement advice. Claims bounded to the results reported in the cited papers unless explicitly stated otherwise.
Technical Appendix
Appendix Table of Contents
- Author and Source Credibility
- Corpus Reviewed
- Citability Snapshot
- Technical Term Definitions
- Method Comparison Matrix
- Evidence Maturity Map
Author and Source Credibility
All four papers appear in peer-reviewed venues: Neural Networks (Elsevier, Carles-Bou), ICASSP (IEEE, Butler), IEEE Big Data (Daley), and ACM TELO (Wang). Venue quality ranges from top journal (Neural Networks) to workshop-track conference (IEEE Big Data). None is a predatory or non-archival publication.
Corpus Reviewed
- Carles-Bou, J.L. and Carmona, E.J. (2026) ‘Achieving faithful explainability in feedforward neural networks through accurately computed feature attribution’, Neural Networks, 195, 108277. doi:10.1016/j.neunet.2025.108277.
- Butler, K., Feng, G. and Djurić, P.M. (2026) ‘Higher-order feature attribution: bridging statistics, explainable AI, and topological signal processing’, in ICASSP 2026. IEEE. doi:10.1109/ICASSP55912.2026.11461829.
- Daley, B., Ratul, Q.E.A., Serra, E. and Cuzzocrea, A. (2022) ‘GAPS: generality and precision with Shapley attribution’, in 2022 IEEE International Conference on Big Data (Big Data). IEEE. doi:10.1109/BigData55660.2022.10021127.
- Wang, Z., Huang, C., Li, Y. and Yao, X. (2024) ‘Multi-objective feature attribution explanation for explainable machine learning’, ACM Transactions on Evolutionary Learning, 4(1), Article 2. doi:10.1145/3617380.
Citability Snapshot
| Criterion | FACE | Higher-Order IG | GAPS | MOFAE |
|---|---|---|---|---|
| Methodology | Exact computation | Operator theory | Reward optimisation | MOO + evolution |
| Venue | Neural Networks | ICASSP | IEEE Big Data | ACM TELO |
| Empirical breadth | Multiple datasets | 2 tabular datasets | 2 datasets | 8 UCI datasets |
| Architecture support | FNN only | Differentiable | Any (RF tested) | Any |
| Production readiness | High (for FNNs) | Low | Low to Medium | Low |
Technical Term Definitions
- Integrated Hessian
- The second-order extension of Integrated Gradients, measuring how the importance of one feature changes with the value of another by integrating the mixed partial derivative along the interpolation path.
- NSGA-III
- A reference-point-based multi-objective evolutionary algorithm that maintains diversity in the Pareto front by guiding search toward well-spread reference directions in objective space.
- Hadamard product
- An element-wise multiplication of two matrices or vectors of the same dimensions, used in FACE to combine the composite weight matrix with the input.
- ICC2 (Intraclass Correlation Coefficient type 2)
- A measure of absolute agreement between two sets of ratings, used by Carles-Bou and Carmona to quantify the fidelity of their computed attributions against ground-truth model behaviour.
Method Comparison Matrix
| Property | FACE | Higher-Order IG | GAPS | MOFAE |
|---|---|---|---|---|
| Exact or approximate | Exact | Approximate (per-order) | Approximate (Shapley) | Approximate (evolution) |
| Handles interactions | No (first-order only) | Yes (any order) | Implicitly | Via faithfulness |
| Model access needed | Weights | Gradients | Predictions | Predictions |
| Compute cost per point | O(d) | O(d²) per order | Variable | ~6 seconds |
| Hyperparameters | 0 | Order k | 3 reward weights | NSGA-III parameters |
Evidence Maturity Map
- Proof-based (verified within assumptions): (a) FACE exactness for piecewise-linear FNNs; (b) higher-order IG completeness property.
- Demonstrated with empirical evidence (bounded): (a) FACE speed and fidelity on multiple datasets; (b) MOFAE Pareto dominance over comparators on 8 UCI datasets; (c) GAPS generality/precision improvement on UNSW-NB15.
- Partial or contradictory evidence: GAPS on ICS Power System (fails to outperform SHAP).
- Inferred synthesis (not directly tested): (a) scalability of higher-order IG to high-dimensional data; (b) production readiness of MOFAE under latency constraints; (c) applicability of FACE beyond FNN architectures.
References
- [1]K. Butler, G. Feng and P. M. Djurić, Higher-Order Feature Attribution: Bridging Statistics, Explainable AI, and Topological Signal Processing, in ICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5261–5265, n.d. doi: 10.1109/ICASSP55912.2026.11461829. Accessed: 14 June 2026.
- [2]J. L. Carles-Bou and E. J. Carmona, Achieving faithful explainability in feedforward neural networks through accurately computed feature attribution, vol. 195, pp. 108277, 2026. doi: 10.1016/j.neunet.2025.108277. Accessed: 14 June 2026.
- [3]B. Daley, Q. E. A. Ratul, E. Serra and A. Cuzzocrea, GAPS: Generality and Precision with Shapley Attribution, in 2022 IEEE International Conference on Big Data (Big Data), pp. 5444–5450, n.d. doi: 10.1109/BigData55660.2022.10021127. Accessed: 14 June 2026.
- [4]Z. Wang, C. Huang, Y. Li and X. Yao, Multi-objective Feature Attribution Explanation For Explainable Machine Learning, vol. 4, no. 1, n.d. doi: 10.1145/3617380. Accessed: 14 June 2026.
- [5]S. M. Lundberg and S. I. Lee, A Unified Approach to Interpreting Model Predictions, in Advances in Neural Information Processing Systems 30 (NeurIPS 2017), vol. 30, pp. 4765–4774, 2017.
- [6]M. T. Ribeiro, S. Singh and C. Guestrin, “Why Should I Trust You?”: Explaining the Predictions of Any Classifier, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘16), pp. 1135–1144, 2016. doi: 10.1145/2939672.2939778. Accessed: 14 June 2026.
Continue Reading in This Series
These linked articles extend the same evidence trail and improve navigability for readers and search systems.