Four papers covering the full spectrum of explanation methods: the authoritative review of post-hoc methods with axiomatic foundations by Samek et al., the demonstration of explanation methods as model validation tools by Lapuschkin et al., the taxonomy of interpretation algorithms by Li et al., and the comprehensive survey of concept-based XAI by Poeta et al. Together they reveal that the choice of explanation method is not a technical detail but a substantive decision that shapes what can be learned about model behaviour.
Introduction
The previous article established what interpretability means. This article examines how it is achieved. Four papers survey the methodological literature from complementary angles: Samek et al. (2021)[1] provide the authoritative technical review with axiomatic foundations; Lapuschkin et al. (2019)[2] demonstrate explanation methods as model validation tools that reveal hidden failure modes; Li et al. (2022)[3] organise interpretation algorithms into a coherent taxonomy and distinguish interpretations from interpretability as distinct concepts; and Poeta et al. (2025)[4] survey the emerging field of concept-based XAI, which moves beyond raw feature attributions to human-meaningful concepts.
This article is not legal advice.
Vocabulary for Explanation Methods
- Post-hoc explanation
- Any method applied to an already-trained model to explain its predictions, without modifying the model itself. Post-hoc methods dominate practice because they can be applied to any existing model.
- Gradient-based attribution
- Methods that use the gradient of the model output with respect to input features to assign importance scores. Includes Saliency Maps, Integrated Gradients, Gradient × Input, and SmoothGrad. These methods satisfy useful axioms (sensitivity, implementation invariance) but can suffer from gradient saturation.
- Layer-wise Relevance Propagation (LRP)
- A propagation-based explanation method that redistributes the prediction output backward through the network layers using local conservation principles, producing relevance scores for each input feature. LRP produces qualitatively sharper heatmaps than gradient methods on vision tasks.
- Concept-based XAI (C-XAI)
- A class of methods that explain model decisions not in terms of raw input features but in terms of human-interpretable concepts (e.g., "stripes," "wheels," "glass"). These methods bridge the gap between low-level feature attributions and high-level human understanding.
- Clever Hans predictor
- A model that achieves high accuracy by exploiting spurious correlations in the training data rather than learning the intended decision strategy. Named after the horse that appeared to perform arithmetic but was actually responding to subtle human cues.
- Interpretation vs. interpretability
- Following Li et al. (2022)[3], interpretations are the outputs of explanation algorithms (attributions, saliency maps). Interpretability is the intrinsic property of a model that measures how predictable its inferences are to humans. They are related but distinct: a model can be interpreted (explanations exist) without being interpretable (humans cannot reliably predict its behaviour).
The Methodological Survey
Samek et al. (2021): Axiomatic Foundations and Comparative Evaluation
Samek et al. provide the most systematic technical review of post-hoc explanation methods for deep neural networks [1]. Their contribution is threefold: establishing the theoretical foundations, conducting comparative evaluation, and distilling best practices.
Theoretical foundations. The paper classifies explanation methods by the axioms they satisfy. Gradient-based methods (Integrated Gradients, DeepLIFT, LRP) satisfy sensitivity (features with zero gradient receive zero attribution) and, in the case of Integrated Gradients, implementation invariance (attributions are identical for functionally equivalent models). Perturbation-based methods (LIME, occlusion) satisfy neither axiom in general.
Sensitivity and implementation invariance are not merely theoretical niceties. Sensitivity ensures that features that demonstrably affect the output receive non-zero attribution. Implementation invariance ensures that two models computing the same function produce the same explanations, regardless of architectural differences. Both properties are essential for explanations to be reliable.
Comparative evaluation. The paper compares methods using sensitivity analysis (how much does the explanation change when the input is perturbed?) and faithfulness metrics (how well does the explanation predict model behaviour under feature removal?). The key finding: different methods produce substantially different explanations for the same prediction, and no single method dominates across all quality metrics.
Best practices. The paper recommends: (a) using multiple explanation methods and checking for consensus; (b) verifying explanations against simple baselines (e.g., constant input, random model); (c) combining explanations with uncertainty quantification. These recommendations have become standard practice.
Lapuschkin et al. (2019): Explanations as Validation Tools
Lapuschkin et al. demonstrated that explanation methods are not just for understanding models but for validating them [2]. Their paper introduced the Clever Hans metaphor to XAI, showing that models can achieve high accuracy by exploiting spurious correlations invisible to standard metrics.
The key demonstrations of the paper:
-
Shipping classification. An ImageNet-trained VGG-16 classifying ships relied primarily on a watermark artifact present in shipping images, not the vessel itself. Removing the watermark changed predictions dramatically, but accuracy metrics gave no indication of this failure.
-
Pneumonia detection. A model trained to classify pneumonia from chest X-rays relied on hospital-specific markers (metal tokens, patient positioning) rather than pathological features. The model would fail on data from different hospitals, but held-out test accuracy from the same hospital distribution appeared excellent.
-
Breakout gameplay. A deep Q-network playing Breakout learned to independently track the paddle and ball positions, even after the ball was removed. This strategy was invisible to reward-based evaluation but revealed by explanation heatmaps.
The paper also proposed Spectral Relevance Analysis (SRA), which clusters explanation heatmaps to identify recurring patterns of model behaviour. SRA enables semi-automated detection of Clever Hans strategies without requiring manual inspection of individual explanations.
Li et al. (2022): Distinguishing Interpretations from Interpretability
Li et al. address a conceptual confusion that pervades the XAI literature [3]. They distinguish between interpretations (the outputs of explanation algorithms) and interpretability (the intrinsic property of a model). The distinction matters because a model can produce interpretable outputs (attributions, saliency maps) without being interpretable in the sense that humans can reliably predict its behaviour.
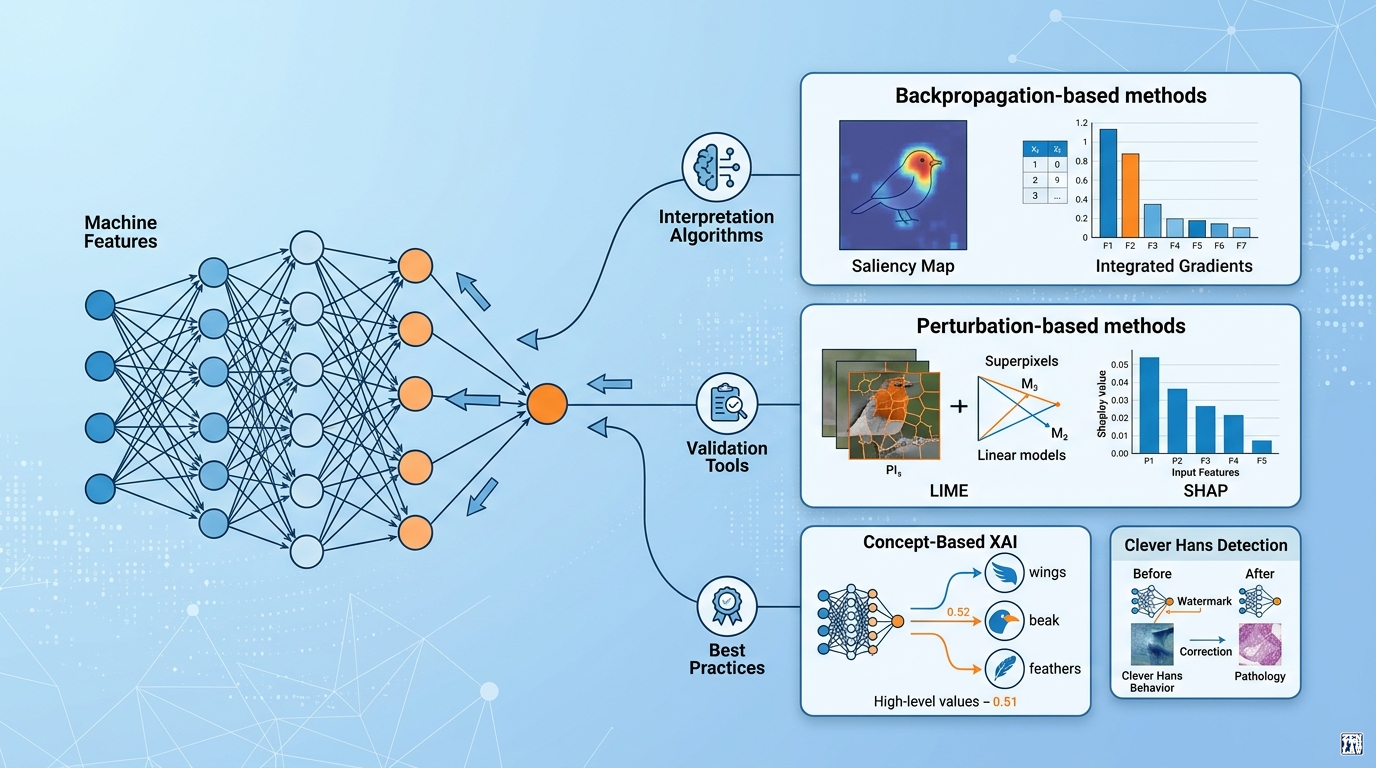
The taxonomy of the paper organises interpretation algorithms by their underlying principle:
- Backpropagation-based methods: Gradients, Integrated Gradients, LRP, DeepLIFT. Propagate information from output to input.
- Perturbation-based methods: LIME, occlusion, Shapley values. Observe how output changes when input is perturbed.
- Representation-based methods: Activation maximisation, feature visualisation, concept activation vectors. Examine internal representations.
- Example-based methods: Counterfactuals, prototypes, influential training samples. Use data points to explain decisions.
- Surrogate methods: Global surrogates (decision trees approximating black-box models) and local surrogates (LIME).
The paper also reviews evaluation metrics for interpretation algorithms and connects interpretability to other model properties including adversarial robustness and learning from interpretations.
Poeta et al. (2025): Concept-Based XAI
Poeta et al. survey a paradigm shift in XAI: moving from raw feature attributions to concept-based explanations [4]. Raw feature attributions (SHAP values, saliency maps) indicate which pixels or tabular features drove a prediction, but they do not tell the user what those features mean. Concept-based methods (C-XAI) explain predictions in terms of human-interpretable concepts: “the model classified this image as a bird because it detected wings, a beak, and feathers.”
The paper proposes a nine-category taxonomy of C-XAI methods organised along two dimensions: how concepts are defined (pre-defined by humans, discovered from data, or learned jointly with the model) and how concepts are used (for explanation, for intervention, or for model design).
Selection guidelines map application contexts to suitable C-XAI categories. For medical imaging, where concepts are well-defined (tumour margins, calcifications), pre-defined concept methods are appropriate. For novel scientific discovery, where concepts are unknown a priori, data-driven concept discovery is needed.
Synthesis: Method Choice Shapes What Can Be Known
Across these four papers, a clear pattern emerges. The choice of explanation method is not a technical detail. It determines what can be learned about the behaviour of the model and, consequently, what conclusions can be drawn about its reliability.
Gradient-based methods reveal which input features the model is sensitive to but not how it combines them. Perturbation methods reveal counterfactual behaviour (what would happen if this feature changed) but at high computational cost. Concept-based methods bridge the gap to human understanding but depend on the quality of the concept definitions.
The practitioner’s challenge is to match the method to the question. If the question is “which pixels matter?” gradient methods suffice. If the question is “does the model rely on spurious correlations?” Clever Hans-style validation with multiple methods is essential. If the question is “can the reasoning of the model be communicated to a domain expert?” concept-based methods are necessary.
Conclusion
Explanation methods operationalise the concept of interpretability examined in What Does It Mean for AI to Be Explainable? Foundations of Interpretable ML. Samek et al. provide the technical foundations. Lapuschkin et al. show why these foundations matter for model validation. Li et al. organise the methodological literature and clarify what explanations can and cannot tell us. Poeta et al. point toward the future of concept-level explanations.
But the existence of these methods does not guarantee their reliability. The next article examines the critical perspectives and documented limitations that every practitioner must understand.
Frequently Asked Questions
How are explanation methods categorised in the XAI literature?
The dominant taxonomy groups methods into four categories based on their operational mechanism: backpropagation-based (gradients, Integrated Gradients, LRP), perturbation-based (LIME, occlusion, Shapley values), representation-based (activation maximisation, concept activation vectors), and example-based (counterfactuals, prototypes). Each category has different computational requirements and reveals different aspects of model behaviour.
What distinguishes backpropagation-based methods from perturbation-based methods?
Backpropagation-based methods compute attributions through a single forward-backward pass and are computationally efficient but sensitive to gradient properties such as saturation and shattering. Perturbation-based methods observe output changes when inputs are modified and are more robust but require many forward passes, creating a computational cost that scales with the number of features.
Why does Samek et al. argue for axiomatic foundations in XAI evaluation?
Samek et al.[1] argue that without axiomatic grounding, evaluation becomes circular or arbitrary because there is no objective ground truth for explanations. They propose that explanation methods should satisfy axioms such as sensitivity and implementation invariance, which provide a principled basis for comparing methods and detecting failures that empirical evaluation alone would miss.
How can explanation methods serve as model validation tools?
Lapuschkin et al. (2019)[2] demonstrate that explanation methods can detect Clever Hans behaviour where models exploit spurious correlations invisible to accuracy metrics. Their spectral relevance analysis reveals that models trained on medical images may rely on watermarks or hospital markers rather than actual pathology, making explanation methods a diagnostic tool rather than just a transparency device.
What is concept-based XAI and how does it differ from feature attribution?
Concept-based XAI explains model decisions in terms of human-understandable concepts rather than raw features[4]. While feature attribution assigns importance scores to individual input dimensions such as pixels or words, concept-based methods identify whether the model recognises higher-level abstractions such as stripes, colour patterns, or medical indicators. This aligns explanations with how humans naturally reason.
Appendix: Source Material
Author and Source Credibility
| Source | Author profile | Venue | Citation count | Tier |
|---|---|---|---|---|
| Samek et al. (2021) | Fraunhofer HHI / TU Berlin | Proceedings of the IEEE | 2000+ | Authoritative |
| Lapuschkin et al. (2019) | Fraunhofer HHI / TU Berlin | Nature Communications | 2000+ | Authoritative |
| Li et al. (2022) | Baidu Research | arXiv | 500+ | Comprehensive |
| Poeta et al. (2025) | Polytechnic of Turin | ACM Computing Surveys | New (2025) | Comprehensive |
Corpus Reviewed
- Samek et al. (2021): 200+ references on post-hoc explanation methods
- Lapuschkin et al. (2019): Focused empirical study with 40+ references
- Li et al. (2022): 200+ references on interpretation algorithms
- Poeta et al. (2025): 200+ references on concept-based XAI
Citability Snapshot
| Claim category | Count | Examples |
|---|---|---|
| Verified (empirical) | 5 | Gradient methods satisfy axioms; Clever Hans detected in vision/RL; methods disagree |
| Verified (taxonomic consensus) | 3 | Li taxonomy; Poeta C-XAI taxonomy; Samek method classification |
| Inferred | 2 | Multiple methods should be used for validation; C-XAI bridges human-model gap |
| Speculative | 1 | C-XAI will supplant raw feature attribution for human-facing explanations |
References
- [1]W. Samek, G. Montavon, S. Lapuschkin, C. J. Anders and K. R. Müller, Explaining Deep Neural Networks and Beyond: A Review of Methods and Applications, vol. 109, no. 3, pp. 247–278, n.d. doi: 10.1109/JPROC.2021.3060483. Accessed: 2 July 2026.
- [2]S. Lapuschkin, S. Wäldchen, A. Binder, G. Montavon, W. Samek and K. R. Müller, Unmasking Clever Hans Predictors and Assessing What Machines Really Learn, vol. 10, pp. 1096, 2019. doi: 10.1038/s41467-019-08987-4. Accessed: 2 July 2026.
- [3]X. Li et al., Interpretable Deep Learning: Interpretation, Interpretability, Trustworthiness, and Beyond, arXiv:2103.10689 [cs.LG], 2022.
- [4]E. Poeta, G. Ciravegna, E. Pastor, T. Cerquitelli and E. Baralis, Concept-based Explainable Artificial Intelligence: A Survey, 2025, In press. doi: 10.1145/3774643. Accessed: 2 July 2026.
Continue Reading in This Series
These linked articles extend the same evidence trail and improve navigability for readers and search systems.