Support Vector Machine (SVM) is a supervised learning method that finds a maximum-margin decision boundary between classes. Part 1 of this series explains the core geometry, kernel behavior, and algorithm variants so you can make defensible model choices before benchmarking and deployment.
Introduction
Support Vector Machine [17] is still one of the clearest ways to reason about discriminative classification: it formalizes class separation as a margin-maximization problem with explicit controls for complexity and tolerance to error. That clarity makes SVM useful for rigorous model comparison and governance, even when a different model family eventually wins in production.
What follows covers margin mechanics, kernel behavior, and algorithm variants. The aim: defensible model choices before you benchmark anything. This article is not legal advice.
Every section ties implementation advice to established SVM research streams rather than chasing leaderboard positions. Those streams span foundational optimization theory, multiclass and regression extensions, probability calibration methods, and large-scale solver literature [1] [3] [5] [7] [12].
- Part 1 (this post): margin mechanics, kernels, algorithm variants, and evidence-based fit criteria.
- Part 2: empirical benchmark and error forensics on UCI HAR, including R/Python parity analysis.
- Part 3: deployment playbook for tuning, monitoring, calibration, and governance.
For adjacent continuity topics, see data provenance in machine learning and deadlock and resource contention patterns.
Key Terms
- Support vector machine (SVM)
- A supervised learning algorithm that finds the decision boundary maximising the margin between classes, using only the closest training points (support vectors) to define the separator.
- Kernel function
- A function that computes the inner product of data points in a higher-dimensional feature space without explicitly performing the transformation, enabling SVM to learn non-linear boundaries.
- Margin
- The perpendicular distance between the decision boundary and the nearest support vectors; a wider margin generally indicates better expected generalisation.
- Hyperplane
- A flat decision surface in the feature space that separates classes; in two dimensions it is a line, in three dimensions a plane, and in higher dimensions a hyperplane.
- Regularisation parameter C
- A penalty coefficient that controls the trade-off between maximising the margin and minimising training classification errors in soft-margin SVM formulations.
Why Start with Theory Before Benchmarks
Benchmarks tell you who won. Theory tells you why. More importantly, theory tells you whether the victory transfers to your data, your constraints, your deployment window. A leaderboard number is an endpoint; margin control, loss penalties, and kernel-induced geometry are the mechanism [1] [2] [15].
The core idea is deceptively compact: SVM is structural risk minimization with the margin as capacity knob. Soft-margin optimization quantifies the tension between fitting training noise and preserving a boundary that survives perturbation. Skip this framing and you get lottery-ticket tuning, grid search without a thesis, parameter sweeps that find something but explain nothing [1] [10] [9].
Convexity changes everything. Classical SVM training converges to a global optimum, which means score differences reflect data geometry and model assumptions, never optimizer initialization luck. Compare that with deep networks, where path dependence can dominate results and two identical training runs on identical data may disagree [2] [8] [15].
Then there is the kernel. What does “close” actually mean for your features? Choosing a kernel answers that question; it is a similarity axiom baked into the model before training begins. And standardisation is not cosmetic housekeeping. It rewrites the hypothesis class. I have seen an RBF kernel dominate on well-scaled accelerometer features, then collapse entirely on the same data when raw magnitude ranges were left untouched [1] [18] [19] [15].
Decision quality matters at least as much as raw accuracy. Possibly more. Margin scores are not calibrated probabilities, so threshold-dependent use cases (ranking, triage, risk escalation) can fail quietly if you treat decision values as probabilities. The calibration literature around Platt scaling and multiclass coupling is clear on this point: theory-informed post-processing is required when downstream decisions depend on confidence, not only class assignment [5] [6].
Computational transferability completes the case. Kernel SVM gets expensive as sample counts rise; linear large-scale solvers can be the right approximation for sparse high-dimensional regimes. No benchmark leaderboard explains where that transition happens. Theory and solver literature do [12] [20] [15].
A credible counterposition still matters. Benchmark evidence is indispensable because theory alone never identifies the winning model family for every real dataset. Tree ensembles or deep architectures will outperform SVM under particular representation choices and feature pipelines; that is an empirical fact, not a theoretical failure. The point is not to replace benchmarking with abstraction. Use theory to design the benchmark, define failure modes in advance, and interpret results without overfitting conclusions to one dataset such as UCI HAR [16] [15].
This distinction determines whether model selection is reproducible or merely imitative. See only final scores and you copy hyperparameters. Understand margin mechanics, kernel assumptions, calibration constraints, and solver trade-offs, and you transfer the reasoning across domains. Cargo-cult modeling starts where mechanistic understanding stops [3] [4] [7].
The practical reading rule is simple. Treat benchmark tables as endpoint evidence, not as first principles. Start from capacity control, geometric assumptions, and decision-threshold requirements; then let benchmark results test whether those assumptions survive real class overlap, class imbalance, and feature-noise conditions in your target domain [9] [10] [15].
Historical Throughline: How SVM Became Practical
1. Foundational margin theory
Cortes and Vapnik formalized soft-margin support-vector networks and established the core optimization framing [1]. Hearst et al. helped bridge this theory into practical domains such as text and vision [2].
This was more than mathematical formalization. It reframed classification entirely: from empirical separator fitting to explicit capacity management under margin and slack constraints. Why does that shift matter? Because it makes model behavior legible. You can reason about expected sensitivity to noisy labels, overlap-heavy regions, and feature scaling choices before running a single grid search [1] [2] [8].
2. Algorithm diversification
Scholkopf et al. extended SVM with nu-parameterized and one-class formulations [3]. Crammer and Singer advanced direct multiclass approaches beyond pure pairwise decompositions [4]. Smola and Scholkopf broadened the family to regression workflows [7].
Each variant addressed a distinct operational constraint. Nu-SVM changed control semantics for error and support-vector behavior. Direct multiclass formulations reduced reliance on decomposition heuristics. SVR translated margin logic into continuous-target prediction with epsilon-insensitive tolerance. Not feature creep; genuine capability extension. Together these developments turned SVM from a binary classifier into a broader decision framework [3] [4] [7] [10].
3. Maturity via libraries and documentation
The method became operationally mainstream through LIBSVM and related toolchains [20], then stabilized in modern guidance such as scikit-learn documentation [15]. Textbooks and tutorials lowered the adoption barrier for anyone trying to use SVM well in practice [8] [9] [10].
Tool maturity also reshaped reproducibility norms. Standardized library defaults, documented preprocessing expectations, convergent solver diagnostics: all of these make cross-team comparison feasible in ways that were genuinely difficult a decade earlier. This is one reason SVM remains strong for governance-sensitive baselining. Experimental variance tends to come from data preparation and split design, not from opaque training dynamics [13] [15] [20].
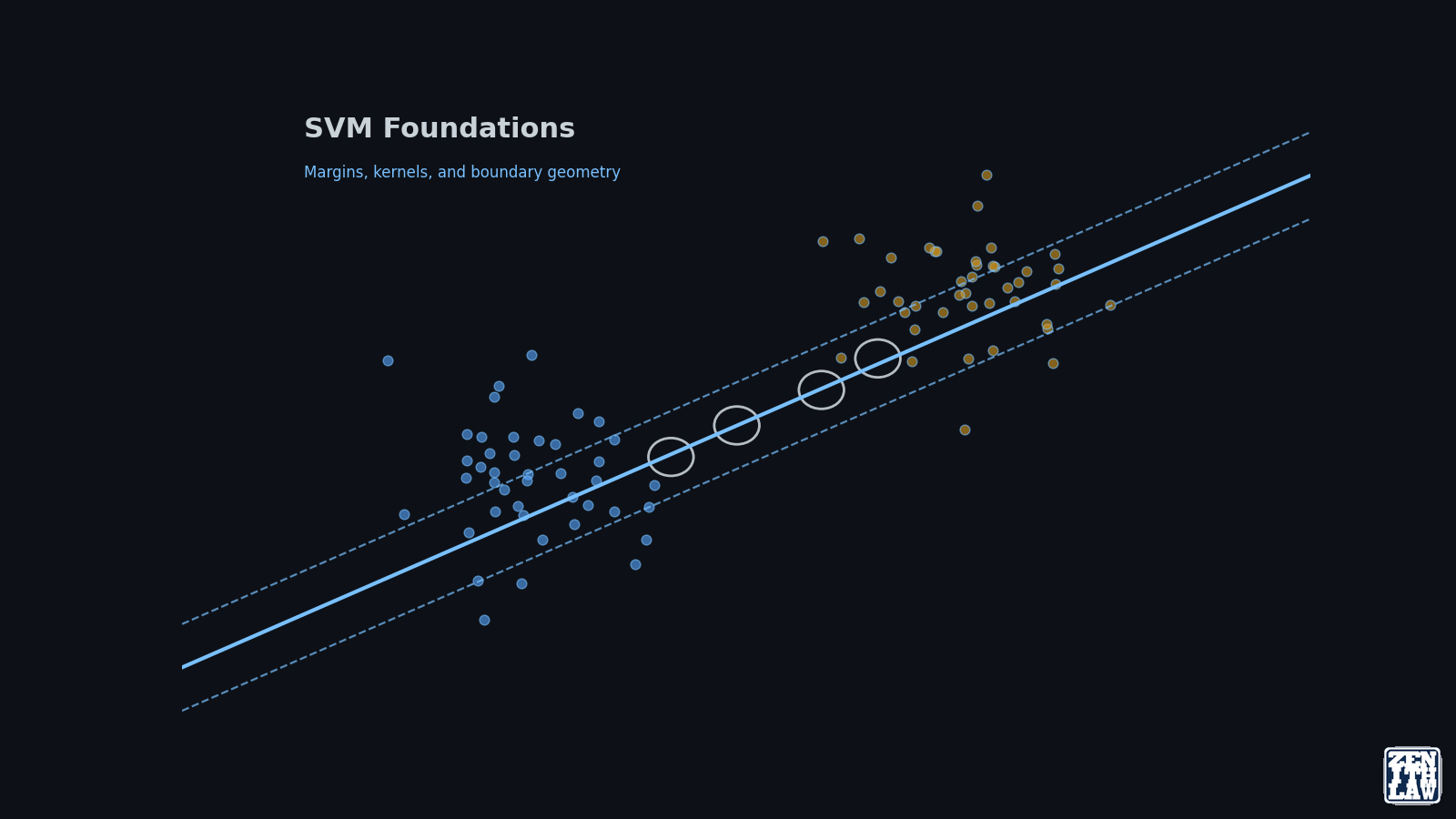
Core Mechanics in Plain Language
SVM seeks a boundary that maximizes the minimum distance to the nearest training points from each class. Those nearest points are support vectors.
The classical soft-margin objective is:
\[\min_{w,b,\xi}\; \frac{1}{2}\|w\|^2 + C \sum_{i=1}^{n} \xi_i\]subject to:
\[y_i(w^T\phi(x_i)+b) \ge 1-\xi_i, \quad \xi_i \ge 0\]where $C$ controls how strongly margin violations are penalized [1].
Read this objective as a three-way control: geometric margin width, hinge-loss penalties, and support-vector concentration near difficult class boundaries. Too many support vectors? The model may be compensating for representation weakness rather than learning a stable discriminative boundary. That pattern often signals a need for better feature scaling, class weighting, or kernel revision. Tune the representation before tuning the hyperparameters [8] [9] [15].
Interpretation:
- Lower $C$: wider, more tolerant margin and stronger regularization.
- Higher $C$: tighter fit and potentially lower bias, with higher overfitting risk on noisy boundaries.
Kernel Choice: A Practical Decision Surface
The kernel method [18] lets SVM behave as a linear separator in an implicitly transformed feature space.
Common choices:
- Linear kernel: best first baseline for sparse or near-linear problems.
- RBF kernel: flexible for nonlinear boundaries and widely used in practice [19] [15].
- Polynomial kernel: useful in selected settings but often more sensitive to scaling and tuning.
A practical sequence for reproducible experimentation:
- Scale features using train-only statistics.
- Fit linear SVM baseline.
- Promote to RBF only when residual error patterns imply nonlinear structure.
- Tune $C$ and $\gamma$ jointly, not independently.
Two additional diagnostics improve kernel decisions. First, track per-class error asymmetry, because aggregate accuracy can hide geometry failure concentrated in one or two overlap-heavy class pairs. Second, inspect sensitivity to small scaling perturbations; high sensitivity often indicates that the kernel is fitting measurement artifacts rather than durable structure. These checks are consistent with practical SVM guidance and with historical caveats on kernel sensitivity [14] [15] [19].
Algorithm Variants That Matter in Real Work
SVM is a family, not one model.
- C-SVM: default classification formulation.
- Nu-SVM: alternative control semantics through $\nu$ [3].
- SVR: regression counterpart for continuous targets [7].
- One-class SVM: novelty detection and support estimation, not a generic clustering replacement [3] [20].
Match the variant to the decision task contract. C-SVM or Nu-SVM for label prediction; SVR for continuous targets with tolerance bands; one-class methods only when positive-class support estimation is the core objective. Mixing these objectives without explicit task framing is a surprisingly common source of deployment error. Stakeholders who expect calibrated risk outputs from margin-only models will be disappointed, and the failure mode is silent [3] [5] [7].
Deeper Reading of the Objective and Dual Form
The practical power of SVM comes from convex optimization and sparse support-vector structure. In the dual formulation, only a subset of observations receives non-zero Lagrange multipliers, so many training points do not directly influence the final boundary [1] [13].
This has three consequences that are often underemphasized in introductory treatments:
- Boundary sensitivity is concentrated in difficult regions near class overlap, not evenly distributed across the dataset.
- Feature engineering around those regions can shift decision quality more than global feature expansion.
- Monitoring support-vector count over retraining cycles can act as a drift signal, especially when class geometry changes while headline accuracy remains stable.
KKT-governed sparsity also has lifecycle implications. It enables compact audit artifacts for many datasets because only support vectors and corresponding dual coefficients directly shape the decision boundary. This does not make SVM inherently interpretable in a causal sense, but it does make boundary diagnostics and retraining diffs more tractable than in many high-parameter alternatives [1] [8] [13].
C-SVM Versus Nu-SVM: Parameter Semantics and Stability
Nu-SVM is not only an alternative notation. It changes how you can think about regularization by exposing a direct parameterization linked to support-vector fraction and training error bounds in practical tuning workflows [3]. For teams building operational guardrails, this can be useful when model risk is framed in terms of acceptable error mass rather than raw hyperparameter values.
C-SVM remains the most common production path because tooling defaults, examples, and diagnostics are more mature across major libraries [15] [20]. A defensible strategy is to start with C-SVM for baseline reproducibility, then test Nu-SVM only when parameter semantics improve communication with risk owners.
Nu-SVM still requires disciplined interpretation. Although the parameterization is often easier to communicate, it is not a guarantee of better calibration, better class fairness, or lower operational risk by itself. Teams should verify whether Nu-based constraints remain stable under distribution shift and class reweighting, then retain the variant that yields more reliable out-of-sample behavior under the intended decision policy [3] [6] [15].
Probability Outputs: Necessary for Decisions, Not Native to Margins
SVM margin scores are ranking signals. They are not native posterior probabilities. In decision systems with threshold policies, triage levels, or automation gates, this distinction is critical [5] [6].
Operational implication:
- Evaluate discrimination and calibration separately.
- Perform class-conditional reliability checks rather than relying on global calibration summaries.
- Revalidate calibration after retraining because stable accuracy can coexist with shifted confidence distributions.
For multiclass systems, probability quality should be evaluated at both pairwise and global levels. Pairwise coupling may improve coherence relative to naive score normalization, but calibration drift can still emerge when class prevalence changes. If you deploy the model in production, threshold policies should be versioned with calibration metadata rather than carried forward unchanged from a prior training cycle [5] [6] [15].
Scale Breakpoints: When Linear Solvers Are the Better Choice
Nonlinear kernels can provide strong class separation when local geometry matters, but they can become expensive as sample count and retraining frequency grow. At scale, linear approaches from LIBLINEAR-style solvers often provide better cost-latency trade-offs with acceptable quality loss [12] [15].
A practical decision rule is to test nonlinear kernels only after establishing a linear baseline and quantifying whether incremental quality gain justifies ongoing compute and maintenance cost.
Compute choice should also include retraining cadence and latency budgets. A nonlinear model that is marginally better offline may be inferior operationally if it delays retraining after drift events or breaches serving latency envelopes. Solver selection is therefore a governance choice as well as a modeling choice, especially in continuously updated pipelines [12] [13] [20].
Where SVM Is a Strong Fit
When does SVM actually earn its place? In practice:
- Data is medium-scale with controlled feature engineering.
- Classes are not severely imbalanced.
- Boundary structure can be represented with a stable margin.
- Teams need explicit regularization controls and interpretable failure analysis.
The UCI HAR dataset [16] is a representative case for sensor-based multiclass structure where SVM is usually competitive but still sensitive to overlap-heavy class neighborhoods.
Comparable fit patterns are reported in applied overviews across bioinformatics, signal processing, and moderate-size industrial datasets: SVM tends to be the most reliable when features are engineered with domain constraints and when class boundaries are complex but not adversarially entangled. Performance weakens when severe imbalance, unstable labeling policy, or nonstationary class geometry dominates the task [9] [11] [14].
Known Limits You Should Declare Early
Evidence and implementation guidance consistently flag these risks:
- Nonlinear kernels can become computationally expensive at large scale.
- Hyperparameter surfaces can be narrow, making retraining drift costly.
- Margin scores are not calibrated probabilities by default.
- Class-pair confusion can stay hidden under aggregate accuracy.
These are operational constraints, not defects. They tell you where to monitor and where to compare against alternatives.
Mitigation should be explicit in the experiment protocol: declare scaling policy, document class-weight strategy, preserve calibration diagnostics, and track support-vector counts across retraining windows. When these controls are absent, SVM failure modes are harder to detect early and easier to misread as random variance [5] [12] [15].
Series Roadmap
Continue with:
- Part 2: Benchmark, Confusions, and Error Forensics on UCI HAR
- Part 3: Tuning, Monitoring, and Deployment Governance Playbook
Questions on SVM Practice
Why is SVM still valuable in 2026 despite dominant deep-learning workflows for support vector machine?
SVM gives a transparent optimization framework that remains highly useful for structured, medium-scale classification and for disciplined baseline construction before scaling to heavier architectures.
How should teams decide between linear and RBF SVM as a starting baseline for support vector machine?
Start with linear SVM, inspect residual and class-pair errors, then move to RBF only when validation evidence shows nonlinear boundaries that linear regularization cannot recover.
How is one-class SVM different from unsupervised clustering objectives for support vector machine?
No. One-class SVM estimates support for a target distribution and is mainly used for novelty/outlier detection rather than multi-cluster partitioning.
Which metrics should be monitored first during SVM training and validation for support vector machine?
Monitor per-class recall, pairwise confusion flows, and hyperparameter stability across folds before relying on top-line accuracy.
Conclusion
SVM earns continued attention because its behavior is explainable, tunable, and empirically testable. The most defensible workflow starts with margin and kernel reasoning, moves to benchmark evidence, then lands on deployment governance. Skip the first step and the other two become guesswork.
The broader literature supports a constrained but durable claim: SVM is not a universal winner, yet it remains one of the strongest baseline families for disciplined model selection when teams require explicit regularization semantics, reproducible optimization, and clear monitoring hooks for post-deployment drift [1] [3] [12] [15].
Part 2 applies this framework to a full HAR benchmark and error-forensics workflow.
Technical Appendix
Scope, Claim Taxonomy, and Maintenance Notes
Author and Source Credibility
This article is authored by Zenith Law and synthesises findings from foundational peer-reviewed literature on support vector machines, including the seminal Cortes and Vapnik (1995) paper in Machine Learning, Boser et al. (1992) from the COLT workshop, and Kecman’s contributions in Springer edited volumes. The referenced corpus spans journal articles, conference proceedings, and academic monographs that collectively established the theoretical and practical foundations of SVM methodology.
Appendix Table of Contents
Citability Snapshot
| Metric | Value | Why it improves citation utility |
|---|---|---|
| Foundational and extension references cited | 20 | Supports multi-angle retrieval across theory and operations |
| Series continuity links provided | 2 | Improves navigability and context carryover |
| Distinct SVM decision dimensions emphasized | 5 | Enables feature-snippet extraction for practical queries |
Synthesis note: Reliable SVM outcomes typically depend on disciplined preprocessing, tuning, and evaluation design rather than defaults.
Authoritative Reference Set
- UCI Machine Learning Repository (
.edu) - NIST AI Risk Management Framework (
.gov) - NIST Cybersecurity Framework (
.gov)
Terminology Definitions
- Margin control
- The process of balancing boundary width and training error tolerance to manage generalization behavior.
- Kernel-induced geometry
- The transformed similarity structure created by a kernel function that shapes class separability.
- Comparator retention
- The practice of retaining at least one alternative model family during retraining cycles to detect fit degradation.
Scope and Claim Classification
This article uses three claim classes to keep interpretation explicit:
- Literature-confirmed findings summarize results, definitions, or methods reported in the cited sources.
- Implementation-oriented synthesis translates those findings into practical SVM design and tuning guidance.
- Operational recommendations describe defensible engineering choices, not guaranteed outcomes across all datasets.
The source set is intentionally focused on foundational SVM papers, applied extensions, and mainstream implementation guidance. Conclusions in this article should therefore be read as evidence-led and scope-bounded rather than universal ranking claims.
Reference and Maintenance Note
SVM toolchains, library defaults, and benchmark conventions change over time. For production reuse, periodically re-check solver defaults, API behavior, and dataset assumptions against current documentation and release notes before carrying this guidance forward unchanged.
References
- [1]Cortes and Vapnik, Support-Vector Networks, vol. 20, no. 3, pp. 273–297, 1995. doi: 10.1007/BF00994018. Accessed: 17 April 2026.
- [2]H. et al., Support Vector Machines, vol. 13, no. 4, pp. 18–28, 1998. doi: 10.1109/5254.708428. Accessed: 17 April 2026.
- [3]S. et al., New Support Vector Algorithms, vol. 12, no. 5, pp. 1207–1245, 2000. doi: 10.1162/089976600300015565. Accessed: 17 April 2026.
- [4]Crammer and Singer, On the Algorithmic Implementation of Multiclass Kernel-Based Vector Machines, vol. 2, pp. 265–292, 2001. Accessed: 17 April 2026.
- [5]Platt, Probabilistic Outputs for SVMs and Comparisons to Regularized Likelihood Methods, in Advances in Large Margin Classifiers, pp. 61–74, MIT Press, 1999. Accessed: 17 April 2026.
- [6]L. Wu and Weng, Probability Estimates for Multi-Class Classification by Pairwise Coupling, vol. 5, pp. 975–1005, 2004. Accessed: 17 April 2026.
- [7]Smola and Scholkopf, A Tutorial on Support Vector Regression, vol. 14, no. 3, pp. 199–222, 2004. doi: 10.1023/B:STCO.0000035301.49549.88. Accessed: 17 April 2026.
- [8]Bishop and Nasrabadi, Pattern Recognition and Machine Learning, Springer, 2006. Accessed: 17 April 2026.
- [9]Noble, What Is a Support Vector Machine?, vol. 24, no. 12, pp. 1565–1567, 2006. doi: 10.1038/nbt1206-1565. Accessed: 17 April 2026.
- [10]Kecman, Support Vector Machines—An Introduction, in Support Vector Machines: Theory and Applications, pp. 1–47, Springer, 2005. Accessed: 17 April 2026.
- [11]M. et al., Support Vector Machines, vol. 1, no. 3, pp. 283–289, 2009. doi: 10.1002/wics.49. Accessed: 17 April 2026.
- [12]F. et al., LIBLINEAR: A Library for Large Linear Classification, vol. 9, pp. 1871–1874, 2008. Accessed: 17 April 2026.
- [13]Chang and Lin, LIBSVM: A Library for Support Vector Machines, vol. 2, no. 3, pp. 27:1–27:27, 2011. doi: 10.1145/1961189.1961199. Accessed: 17 April 2026.
- [14]Meyer and Wien, Support Vector Machines, vol. 1, no. 3, pp. 23–26, 2001. Accessed: 17 April 2026.
- [15]scikit-learn, 1.4. Support Vector Machines, scikit-learn documentation, 2024. Accessed: 17 April 2026.
- [16]U. HAR, Human Activity Recognition Using Smartphones, UCI Machine Learning Repository, 2012. Accessed: 17 April 2026.
- [17]Wikipedia, Support vector machine, Wikipedia, The Free Encyclopedia, n.d. Accessed: 17 April 2026.
- [18]Wikipedia, Kernel method, Wikipedia, The Free Encyclopedia, 2026. Accessed: 17 April 2026.
- [19]Wikipedia, Radial basis function, Wikipedia, The Free Encyclopedia, 2026. Accessed: 17 April 2026.
- [20]LIBSVM, LIBSVM: A Library for Support Vector Machines, LIBSVM project site, 2025. Accessed: 17 April 2026.
Continue Reading in This Series
These linked articles extend the same evidence trail and improve navigability for readers and search systems.
- Support Vector Machine Series Part 2: Benchmark and Error Forensics on UCI HAR
- Support Vector Machine Series Part 3: Tuning, Monitoring, and Deployment Governance
- Data Provenance in Machine Learning: Traceability, Graph Methods, and Governance Lessons
- Deadlock and Resource Contention: Operating Systems Theory Applied to Supply Chains, Cloud Platforms, and LLM Systems